Data Vault: Comment se distingue cette nouvelle vision d'entrepôt de données? - Partie 1
Cet article est le premier d'une série d'articles traitant de l'approche Data Vault de modélisation d'entrepôts de données.
Depuis de nombreuses années, deux visions classiques s'affrontent en ce qui concerne la modélisation des entrepôts de données. L’approche Inmon de modélisation d’entrepôt de données d’entreprise par sujet et normalisée et l’approche Kimball de modélisation en étoiles où l’intégration en un entrepôt d’entreprise est assurée par des dimensions conformes et l'usage d'une matrice de bus.
Bien que moins présente que les deux approches classiques, il existe une troisième voie : l’approche de modélisation Data Vault (« par voûtes de données ») préconisée par son inventeur Dan Linstedt depuis le début des années 2000. La modélisation Data Vault se veut une sorte d’approche mitoyenne située entre Inmon et Kimball.
Un modèle Data Vault est composé de trois types d’entités : les hubs, les liens (« links ») et les satellites.
Les hubs sont des concepts d'affaires. Ces entités contiennent les clefs naturelles (clefs d'affaires) qui identifient le concept et qui sont par nature très stables. Elles ne contiennent aucune donnée qui décrit l'entité (celles-ci sont gardées dans les entités satellites décrites plus bas). Elles constituent souvent le point de raccordement (d'où le terme anglais « hub ») entre plusieurs secteurs d'une organisation. La figure 1 montre un exemple de modèle Data Vault. Les entités Position, Employé, Affichage poste et Application sont des hubs.
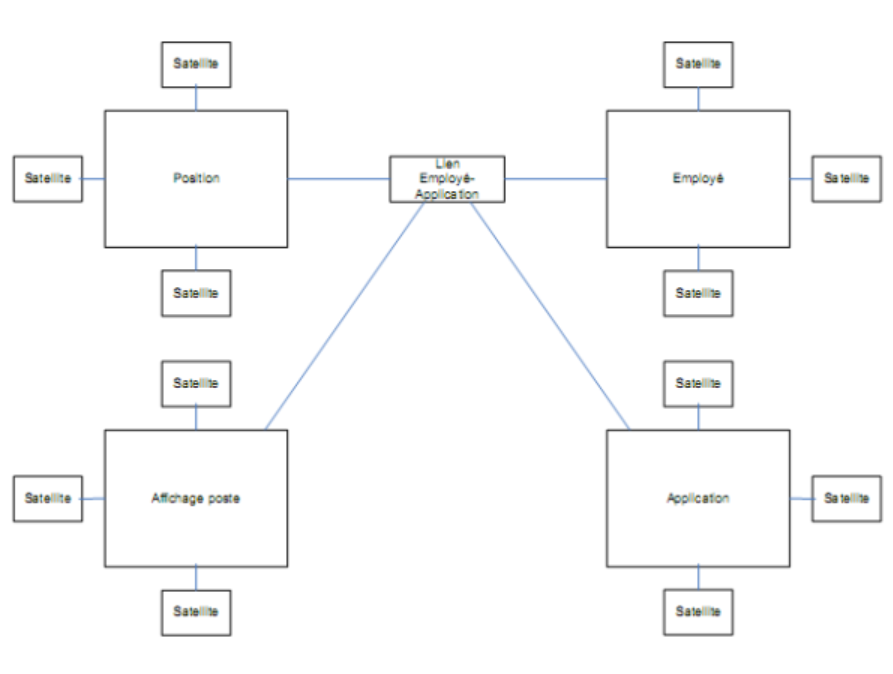
Figure 1 : Exemple de modèle Data Vault
Les liens sont des entités associatives. Elles lient ensemble au moins deux hubs; autrement dit, elles mettent en relation des concepts d'affaires. L'entité Lien Employé-Application de la figure 1 est un exemple de lien.
Les satellites contiennent les données qui décrivent les hubs et les liens à un moment donné et à travers le temps. Ces entités contiennent le contexte (provenant des processus d'affaires) d'un hub ou d'un lien. Comme les données descriptives changent souvent, l'idée des satellites est de conserver les changements lorsqu'ils surviennent. Comme son nom l'indique, un satellite est une entité dépendante (ou faible) toujours en relation avec un hub ou un lien. Inversement, un hub ou un lien doit toujours contenir au moins un satellite pour le décrire.
Une des idées centrales d'un modèle Data Vault consiste donc à séparer les données structurelles (les hubs et les liens entre les hubs) des données descriptives qui définissent le contexte de ces données (les satellites). Les concepts structurels d'une organisation sont ainsi séparés des contextes d'utilisation de ces concepts.
Une autre idée centrale d'un modèle Data Vault est que celui-ci garde intact le contexte des systèmes sources. Les données provenant des sources sont intégrées dans un entrepôt de type Data Vault sans subir de transformations. Les données sont donc chargées rapidement dans leur format brut en incluant la date et la source du chargement. Il est donc possible de reconstituer l'image d'une source à n'importe lequel moment dans le temps. Le fait de ne pas « travailler » la donnée est une des différences fondamentales avec les deux approches classiques. On dit d'un entrepôt Data Vault qu'il s'agit d'un entrepôt de données brutes (« raw datawarehouse »).
L'approche Data Vault offre plusieurs avantages :
- Elle est flexible et résiste aux changements.
- Elle est extensible.
- Les changements dans les sources sont très rapidement reflétés dans l'entrepôt.
- Elle permet facilement de reconstituer une image des données sources à n'importe lequel moment dans le temps.
Dans les prochains articles, nous reviendrons plus en détail sur les motivations de cette approche de modélisation, nous décrirons plus en détail comment modéliser Data Vault et nous comparerons l'approche Data Vault avec les approches en schémas étoilés et par sujet.
The Data Vault approach offers multiple advantages:
- It is flexible and is modification resistant
- It is extendable
- Modifications in the sources are rapidly shown in the warehouse
- It easily allows to reconstitute data source image at any moment in time
In the following articles, we will go into more details on the motivations of this modeling approach and the Data Vault modeling. We will also compare the Data Vault approach with the star schema and the subject approaches.
Autres articles
Intelligence artificielle
IA en supply chain : sans données solides, pas de valeur durable
Mai 2026Nicolas Lepiller
Intelligence artificielle
Vertex AI et l’essor de l’intelligence agentique sur Google Cloud
Avril 2026Islam Touati
Intelligence d'affaires
Migration Tableau vers Power BI : retour d’expérience et innovation avec l’IA
Mars 2026Adrien Chaudé et Adrien Lecellier